We propose a novel feed-forward 3D editing framework called SHAP-EDITOR. Prior research on editing 3D objects primarily concentrated on editing individual objects by leveraging off-the-shelf 2D image editing networks. This is achieved via a process called distillation, which transfers knowledge from the 2D network to 3D assets. Distillation necessitates at least tens of minutes per asset to attain satisfactory editing results, and is thus not very practical. In contrast, we ask whether 3D editing can be carried out directly by a feed-forward network, eschewing test-time optimisation. In particular, we hypothesise that editing can be greatly simplified by first encoding 3D objects in a suitable latent space. We validate this hypothesis by building upon the latent space of Shap-E. We demonstrate that direct 3D editing in this space is possible and efficient by building a feed-forward editor network that only requires approximately one second per edit. Our experiments show that Shap-Editor generalises well to both in-distribution and out-of-distribution 3D assets with different prompts, exhibiting comparable performance with methods that carry out test-time optimisation for each edited instance.
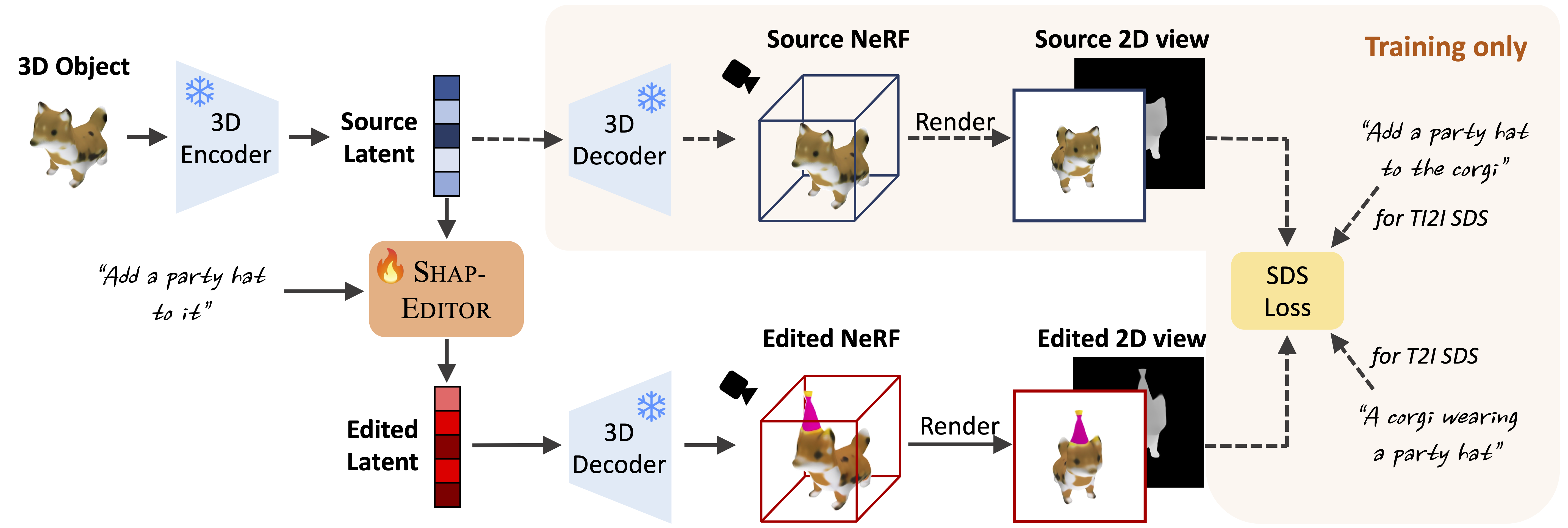
During training, we first use the Shap-E 3D encoder to map a 3D object into the latent space. The source latent and a natural language instruction are then fed into our SHAP-EDITOR producing an edited latent. The edited latent and original latent are decoded into NeRFs and we render a pair of views (RGB images and depth maps) with the same viewpoint for the two different NeRF. The paired views are used for distilling knowledge from the pre-trained 2D editors with our design training objective to our SHAP-EDITOR. During inference, one only needs to pass the latent code to our SHAP-EDITOR, resulting in fast editing.
We provide qualitative comparison with other 3D editing methods. Both the single-prompt and multi-prompt versions of our method achieve superior local and global editing results. Our SHAP-EDITOR can preserve the identity of the original assets, such as the appearance and shape of the "penguin", the fine geometric details of the "vase", and the structure of the "chair".

We provide some interactive mesh results with our method in the following.
We provide some editing results with our method in the following, including global editing and local editing.
@article{chen2023shapeditor,
title={SHAP-EDITOR: Instruction-guided Latent 3D Editing in Seconds},
author={Minghao Chen and Junyu Xie and Iro Laina and Andrea Vedaldi},
journal={arXiv preprint arXiv:2312.09246},
year={2023}
}This research is supported by ERC-CoG UNION 101001212. Iro Laina is also partially supported by the VisualAI EPSRC grant (EP/T028572/1). Junyu Xie is supported by the Clarendon Scholarship. We also appreciate the valuable discussions and support from Paul Engstler, Tengda Han, Laurynas Karazija, Ruining Li, Luke Melas-Kyriazi, Christian Rupprecht, Stanislaw Szymanowicz, Jianyuan Wang, Chuhan Zhang, Chuanxia Zheng, and Andrew Zisserman.
