
Recent diffusion-based generators can produce high-quality images based only on textual prompts. However, they do not correctly interpret instructions that specify the spatial layout of the composition. We propose a simple approach that can achieve robust layout control without requiring training or fine-tuning the image generator. Our technique, which we call layout guidance, manipulates the cross-attention layers that the model uses to interface textual and visual information and steers the reconstruction in the desired direction given, e.g., a user-specified layout. In order to determine how to best guide attention, we study the role of different attention maps when generating images and experiment with two alternative strategies, forward and backward guidance. We evaluate our method quantitatively and qualitatively with several experiments, validating its effectiveness. We further demonstrate its versatility by extending layout guidance to the task of editing the layout and context of a given real image.
We present two types of guidance for controlling the image layout -- forward and backward. In forward guidance, we use a smooth windowing function to bias the original cross-attention map of a specific token towards a user-specified region (such as a bounding box), to "force" the generated image to conform to the desired layout. Backward guidance involves calculating a loss between the cross-attention and bounding box to evaluate whether the attention map follows the desired pattern and updates the latent using back-propagation to guide the attention to focus on a specific region.
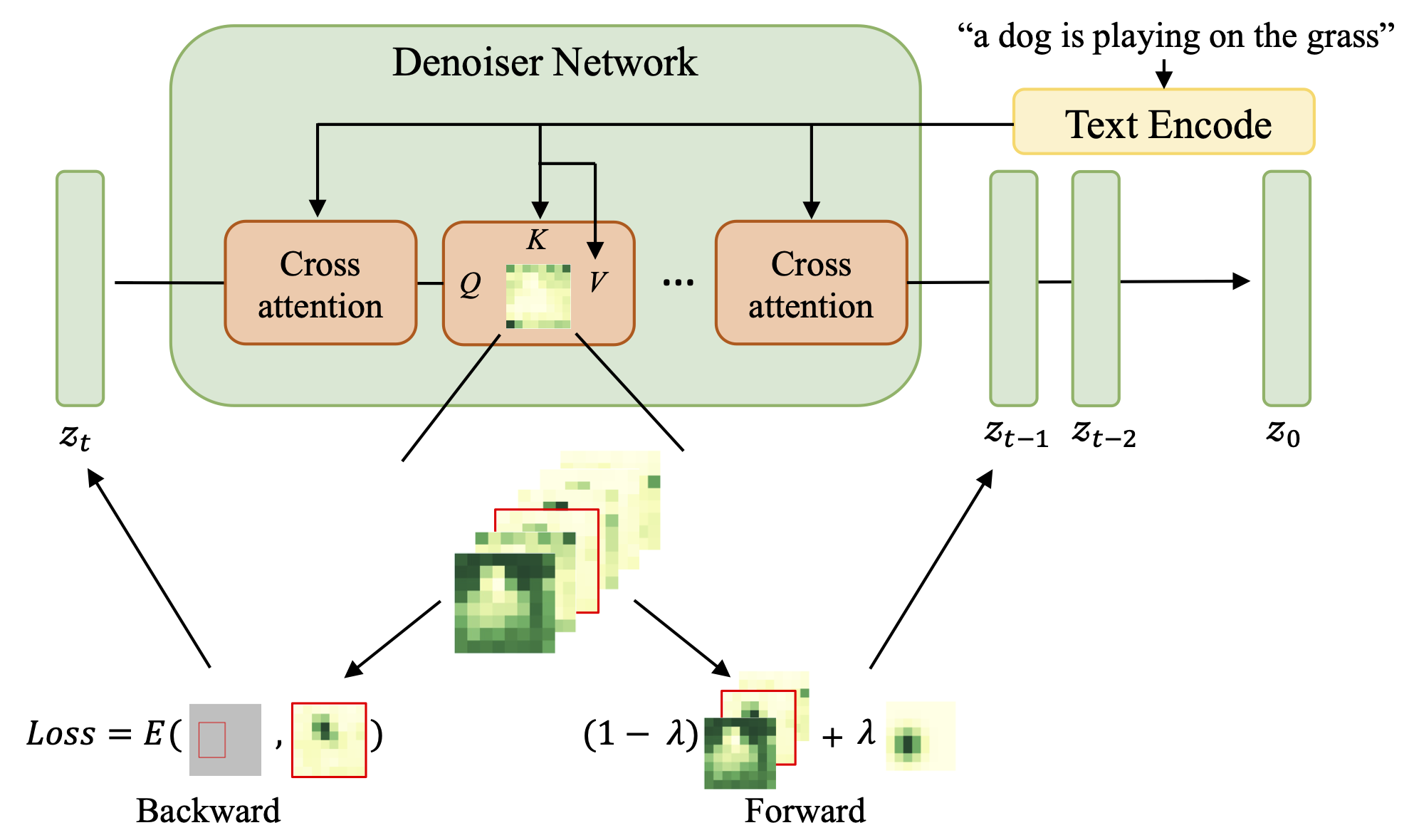
Our method, built on top of Stable Diffusion, achieves image generation with correct spatial relationships. Some examples are from here.

We achieve real image editing based on Dreambooth and Text Inversion. Specifically, we can change the context, location and size of the objects in the original image.

@article{chen2023trainingfree,
title={Training-Free Layout Control with Cross-Attention Guidance},
author={Minghao Chen and Iro Laina and Andrea Vedaldi},
journal={arXiv preprint arXiv:2304.03373},
year={2023}
}This research is supported by ERC-CoG UNION 101001212.