|
Hi, I am currently a final-year DPhil student at Visual Geometry Group, Oxford, advised by Prof. Andrea Vedaldi and Dr. Iro Laina. This summer, I am interning at Meta Superintelligence Labs as a research scientist intern working on video generation model! Before that, I was a Ph.D. student at Stony Brook University, supervised by Prof. Haibin Ling from 2020 to 2022. I received my M.S. from Columbia University in 2020 and B.S. from Beihang University in 2018. I have interned at Meta GenAI, MSR Asia. I am always open to new opportunities and collaborations. Feel free to contact me! |

|
|
I'm interested in computer vision, neural architecture search, generative model and 3D vision. My previous research is mainly about designing efficient and effective neural network automatically, while I am now focusing on generative models. Representative papers are highlighted. |

|
Coming soon. |

|
Dilin Wang, Hyunyoung Jung, Tom Monnier, ..., Minghao Chen, ..., Rakesh Ranjan, Andrea Vedaldi arXiv, 2025 arXiv / bibtex / blog We introduce WorldGen, a system that enables the automatic creation of large-scale, interactive 3D worlds directly from text prompts. WorldGen transforms natural language descriptions into traversable, fully textured environments that can be immediately explored or edited within standard game engines. |

|
Minghao Chen, Jianyuan Wang, Roman Shapovalov, Tom Monnier, Hyunyoung Jung, Dilin Wang, Rakesh Ranjan, Iro Laina, Andrea Vedaldi NeurIPS , 2025 arXiv / bibtex / project page / code We introduce AutoPartGen, a pipeline that generates compositional 3D objects in an autoregressive manner. AutoPartGen can operate automatically or guided by 2D masks. We also show that AutoPartGen can be applied to scene and city generation. |
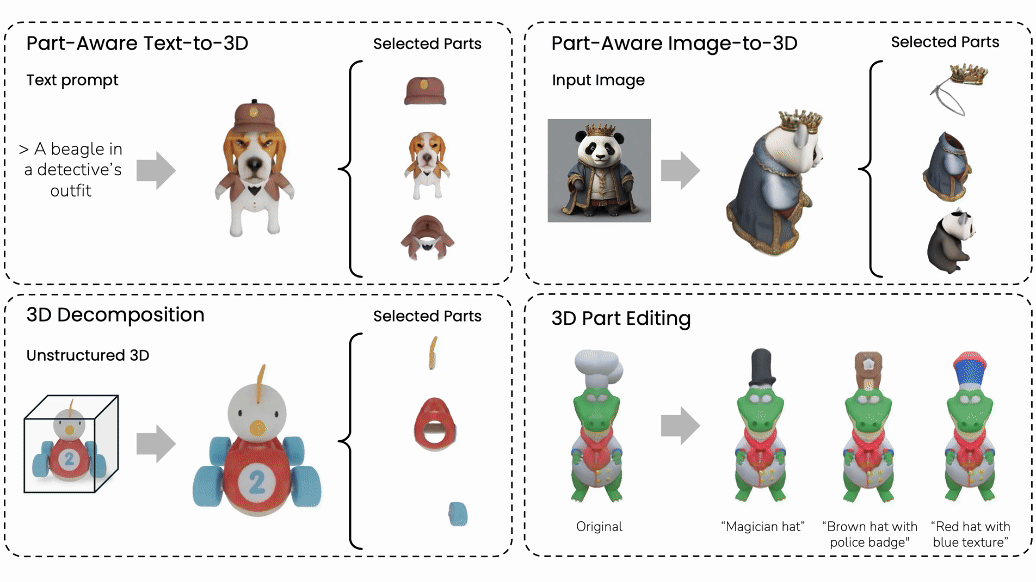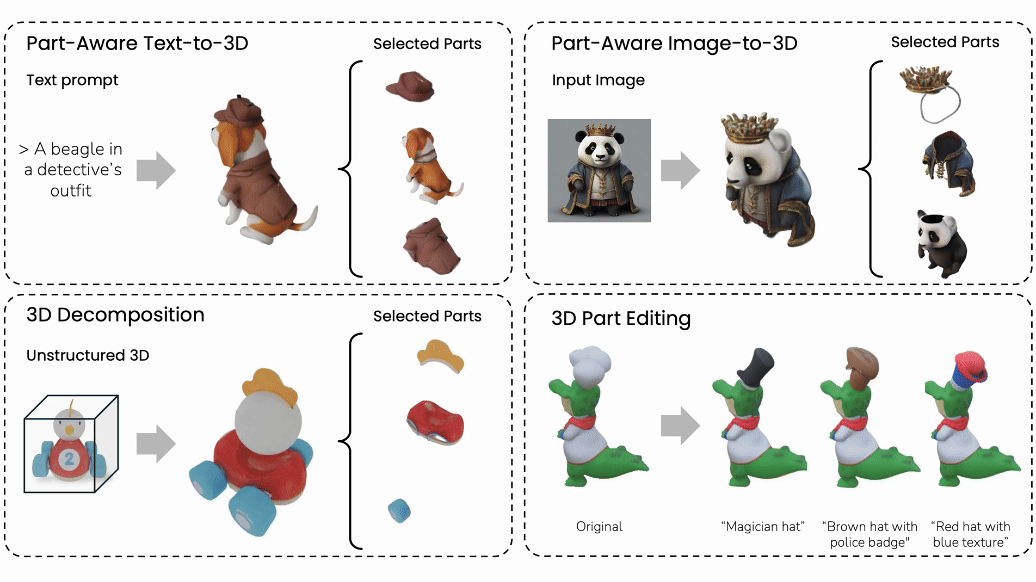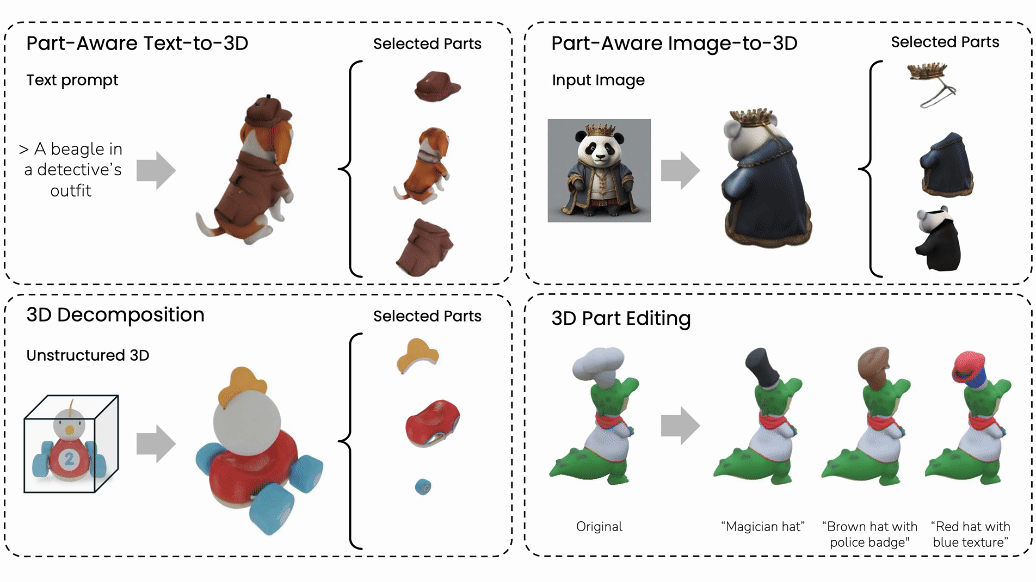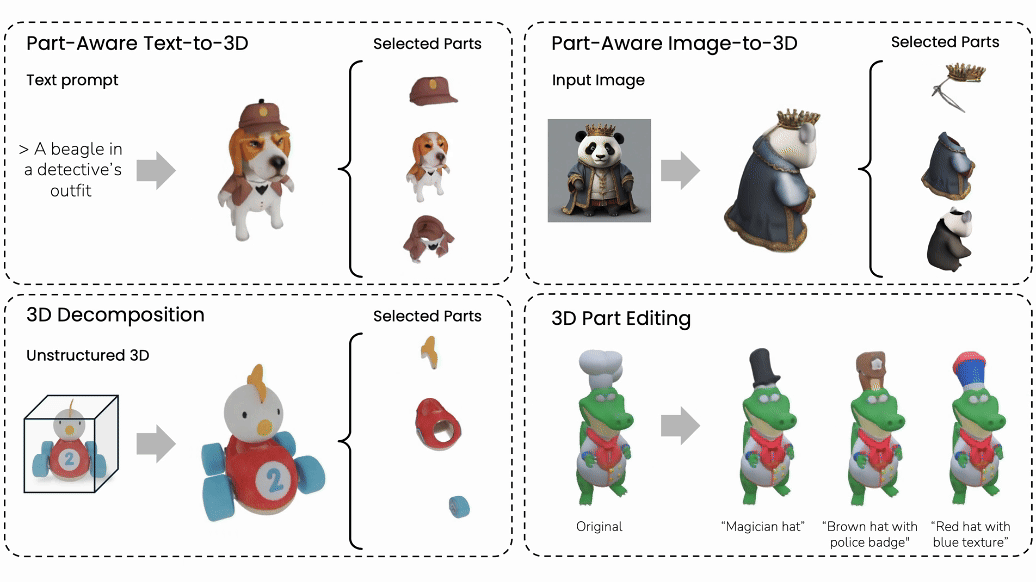
|
Minghao Chen, Roman Shapovalov, Iro Laina, Tom Monnier, Jianyuan Wang, David Novotny, Andrea Vedaldi CVPR, 2025 (Highlight) arXiv / bibtex / project page / video We introduce PartGen, a novel method for compositional/part-level 3D generation and reconstruction from various modalities, including text, image, 3D models. PartGen also enables 3D part editing. |

|
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, David Novotny CVPR, 2025 (Best Paper!!!) arXiv / bibtex / project page / Code / 🤗 Demo / Twitter We present VGGT, a feed-forward neural network that directly infers all key 3D attributes of a scene, including camera parameters, point maps, depth maps, and 3D point tracks, from one, a few, or hundreds of its views. |

|
Minghao Chen, Iro Laina, Andrea Vedaldi ECCV , 2024 arXiv / bibtex / project page / code We introduce Direct Gaussian Editor (DGE), a novel method for fast 3D editing. We consider the task of 3D editing as a two-stage process, where the first stage focuses on achieving multi-view consistent 2D editing, followed by a secondary stage dedicated to precise 3D fitting. |
|
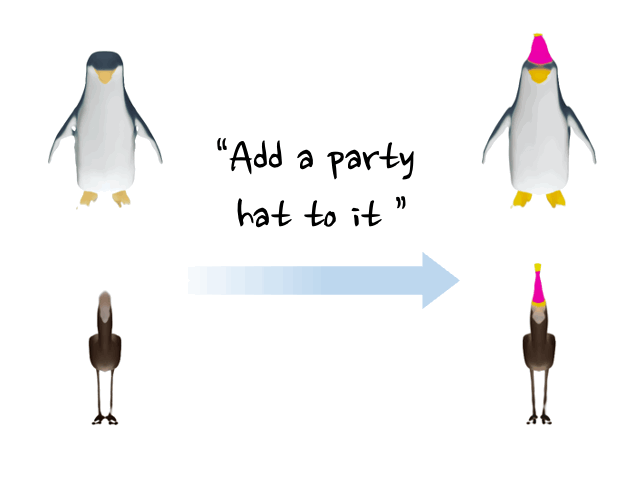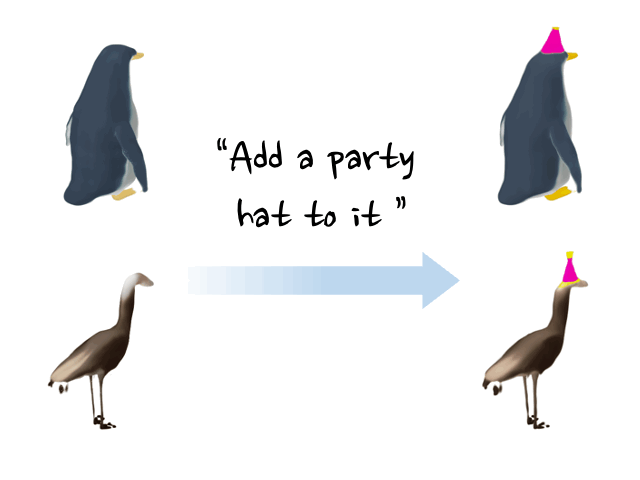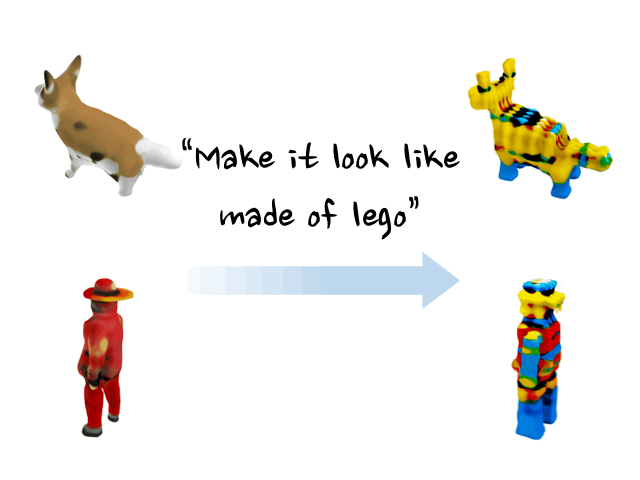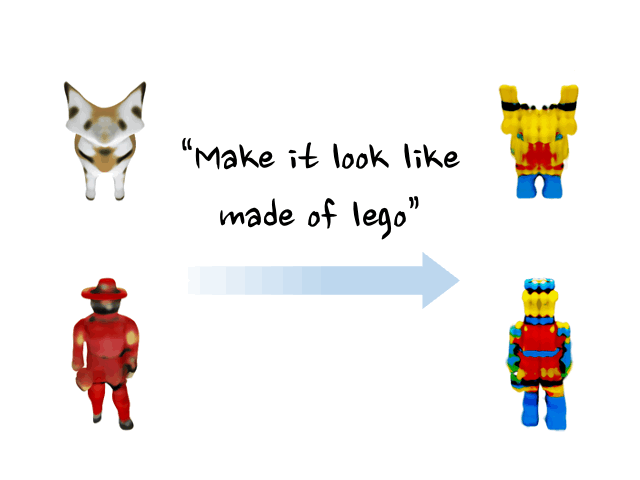
Minghao Chen, Junyu Xie, Iro Laina, Andrea Vedaldi, CVPR , 2024 arXiv / bibtex / project page / code / demo We present a method, named SHAP-EDITOR, aiming at fast 3D editing. We propose to learn a universal editing function that can be applied to different objects within one second. |

|
Minghao Chen, Iro Laina, Andrea Vedaldi WACV, 2024 arXiv / bibtex / project page / code / demo We present a method for controlling the layout of images generated by large pre-trained text-to-image models by guiding the cross-attention patterns. |

|
Bolin Ni, Houwen Peng , Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling ECCV, 2022 (Oral Presentation) arXiv / bibtex / code A new framework adapting language-image foundation models to general video recognition. |
|
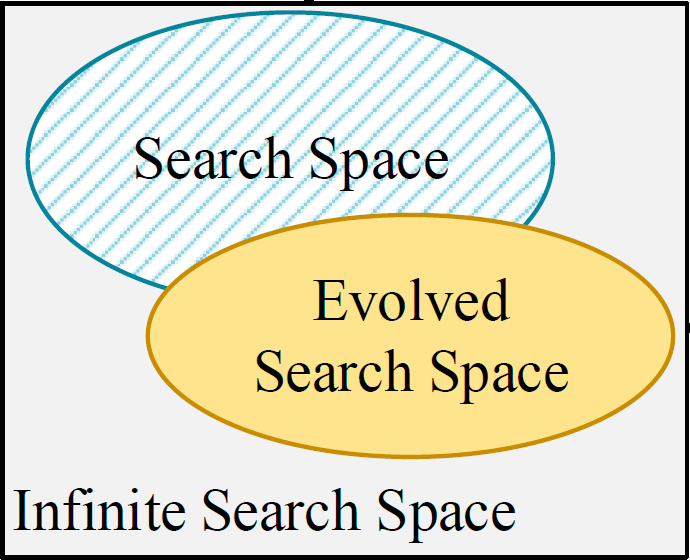
Minghao Chen, Kan Wu, Bolin Ni, Houwen Peng, Bei Liu, Jianlong Fu, Hongyang Chao, Haibin Ling NeurIPS, 2021 arXiv / bibtex / code We propose to search the optimal search space of vision transformer models with AutoFormer training strategy. |
|
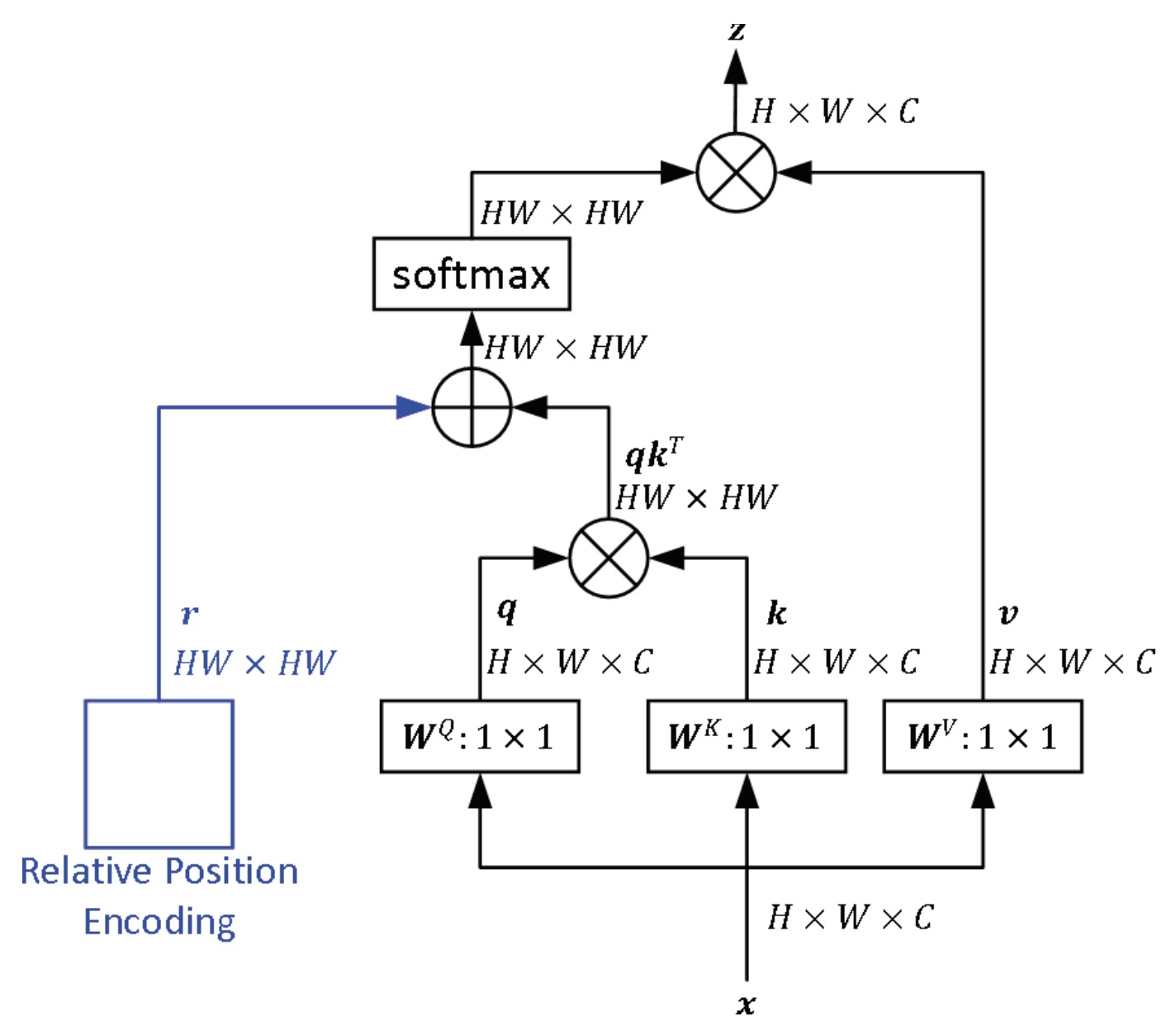
Kan Wu, Houwen Peng, Minghao Chen, Jianlong Fu, Hongyang Chao ICCV, 2021 arXiv / bibtex / code A new relative position encoding methods dedicated to 2D images, considering directional relative distance modeling. |
|
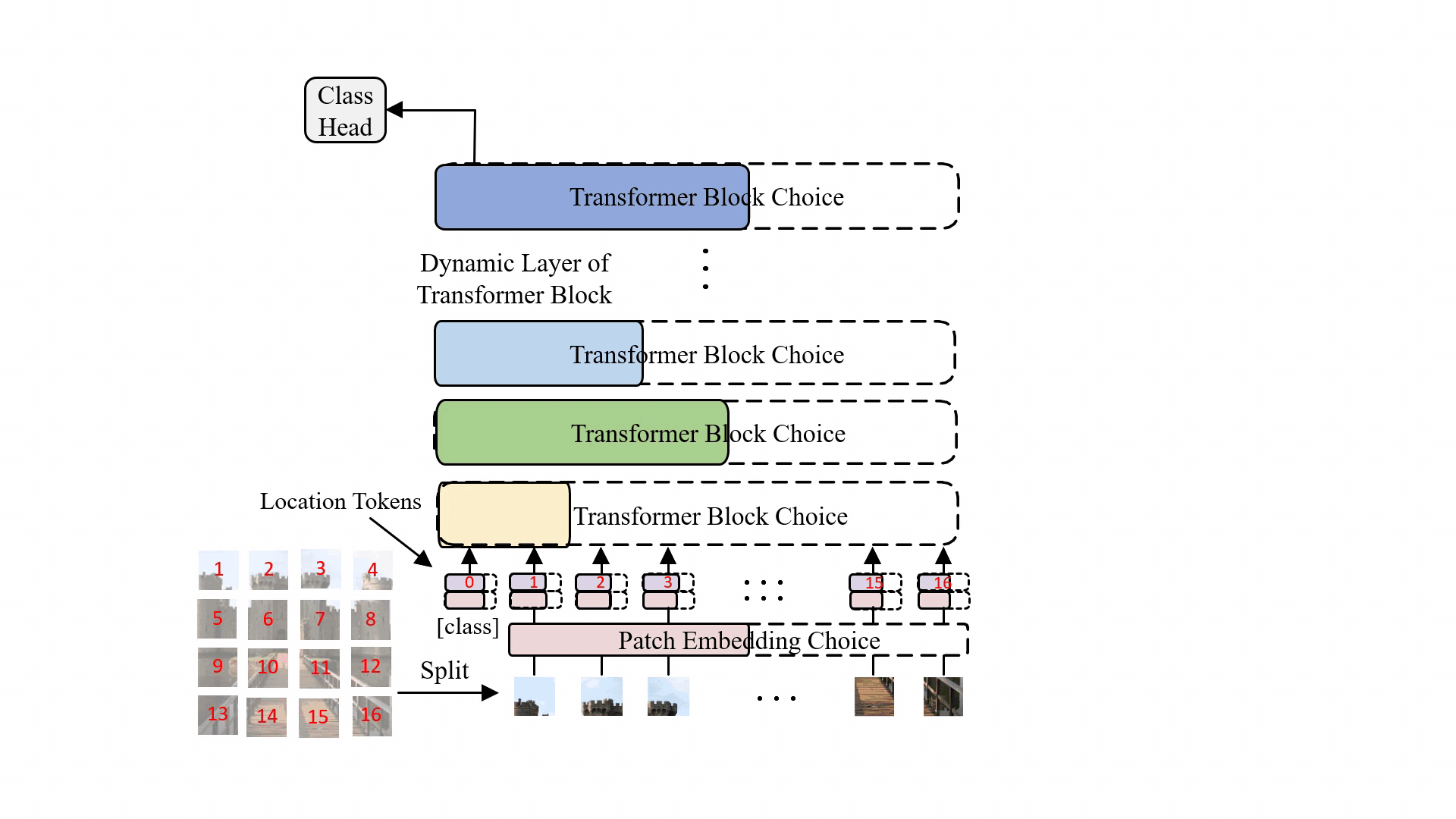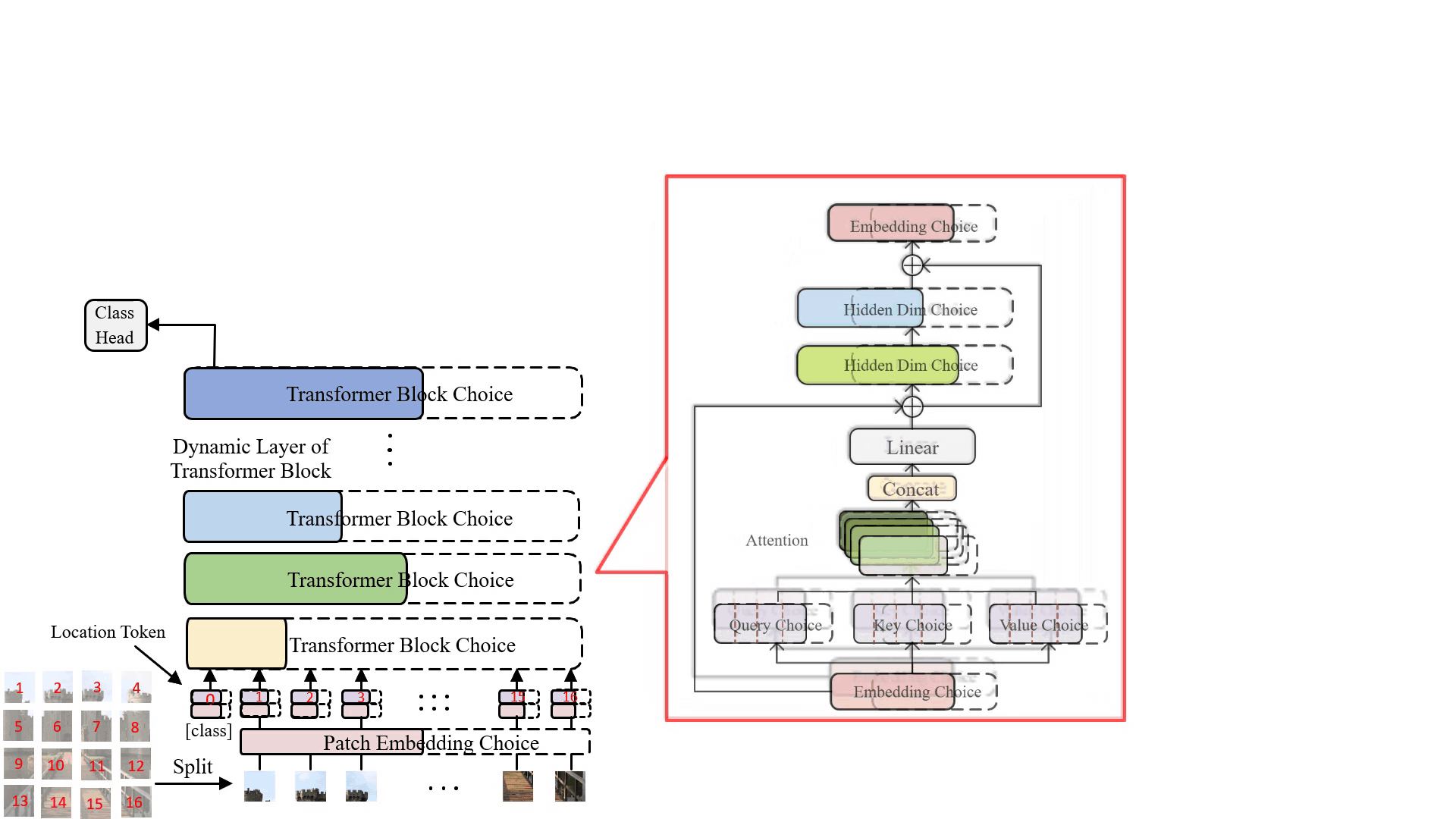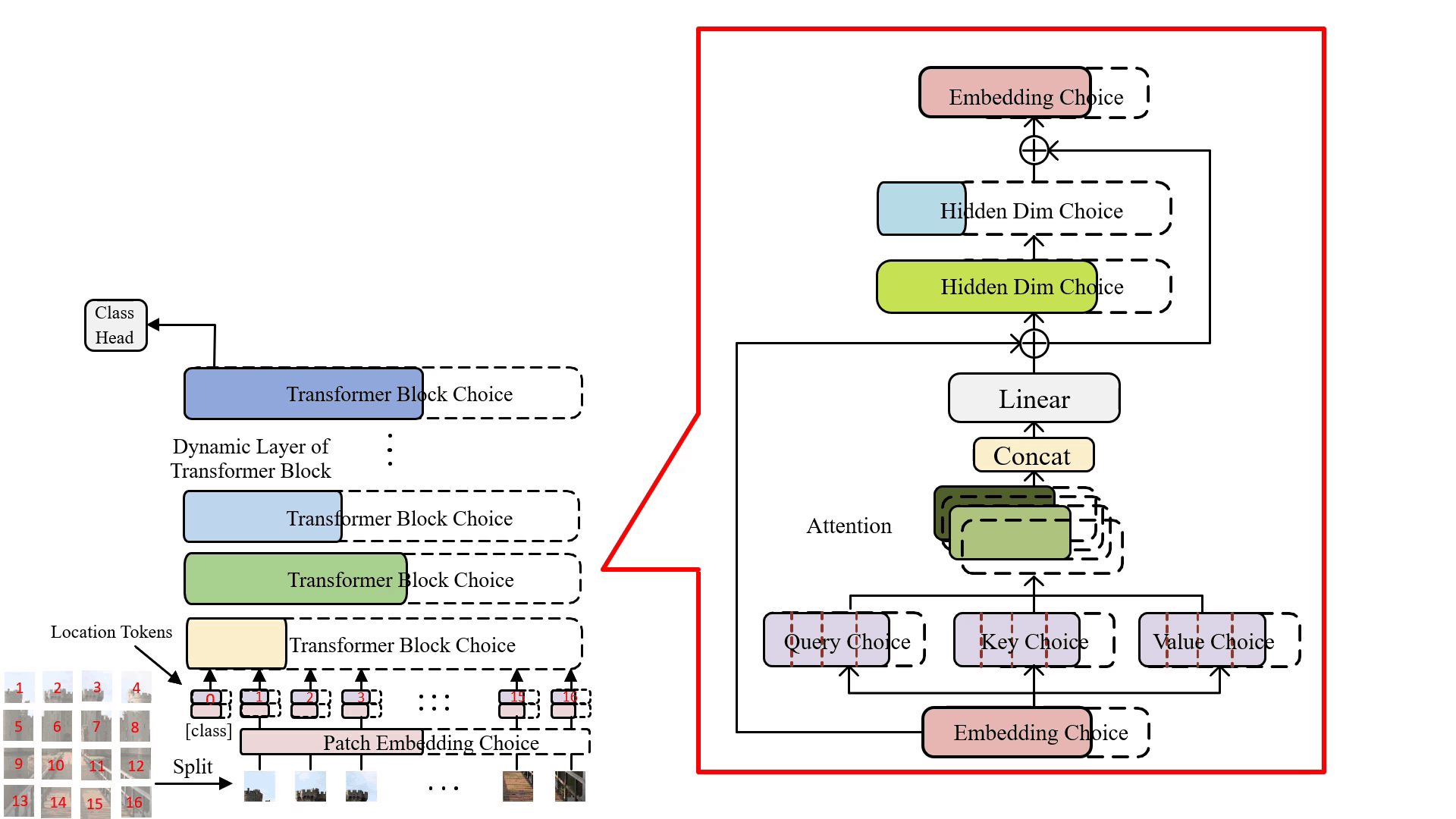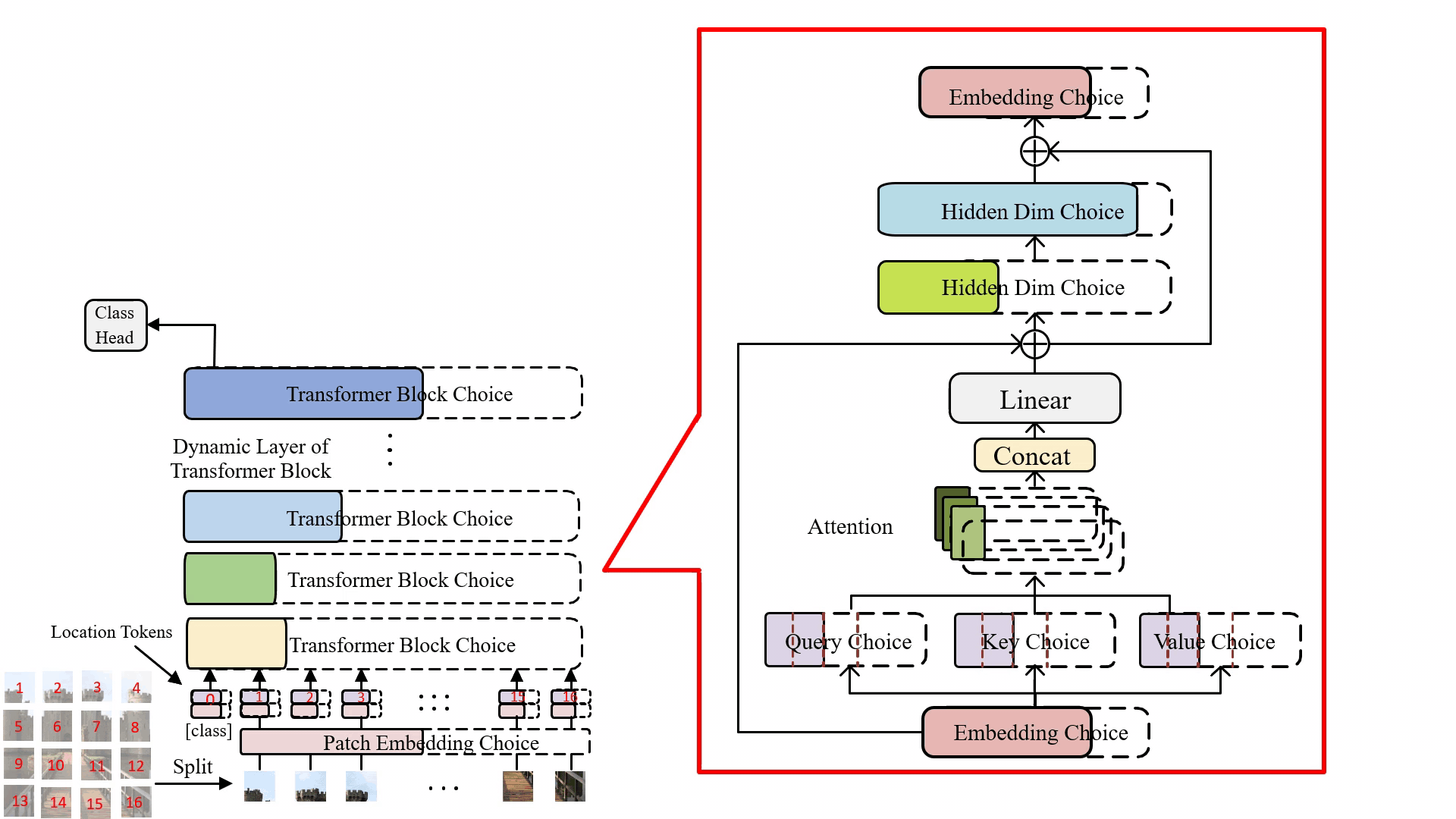
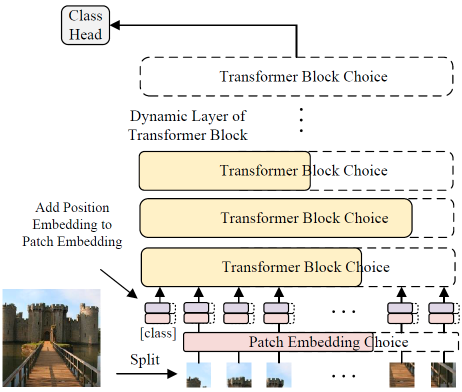
Minghao Chen, Houwen Peng , Jianlong Fu, Haibin Ling ICCV, 2021 arXiv / bibtex / code / A Once-for-all one-shot architecture search framework dedicated to vision transformer search. |
|
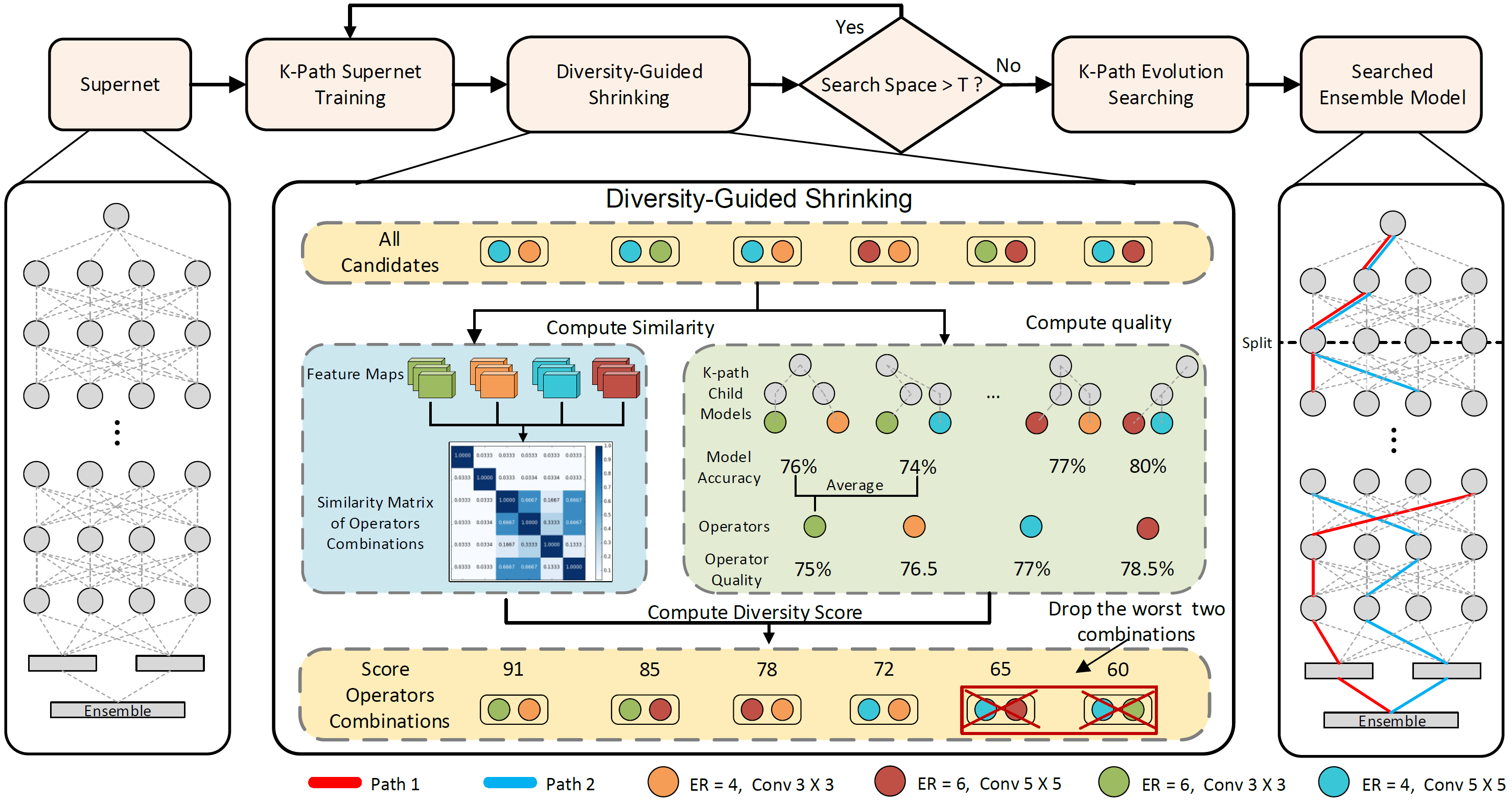
Minghao Chen, Houwen Peng, Jianlong Fu, Haibin Ling CVPR, 2021 arXiv / bibtex / code We present a novel one-shot neural architecture method searching for optimal architectures for model ensemble. |
|
Reviewer CVPR 2022 2023 2024 2025, ECCV 2022 2024, ICCV 2023, NeurIPS 2023, 2024, 2025, ICML 2025, ICLR 2024 2025, WACV 2024, 2025, 3DV 2024, ACM MM 2022, 2021 Teaching Assistant
|
|
This website template is borrowed from Jon Barron. Thanks! |